
New day, new dataset. This time, however, it’s built entirely from scratch (or rather, almost from scratch. I borrowed one from Polygraf AI via Huggingface using the following link, which they removed shortly afterward, probably because they mistakenly made it public, but lucky for us).
Since they decided not to make such an important resource public in the search for Human-Machine language, I am making it public here below:
However, I have modified and enhanced it. This time, not only did I remove the duplicate rows (almost 10k), but I also included three new columns: Id, verbs_human, and verbs_GPT.
| Id | Human | Source | Sys | GPT | verbs_human | verbs_GPT |
| 0 | A signature to this Agreement… | law | Rewrite… | A signature on this Agreement… | [‘deliver’] | [‘submit’, ‘consider’] |
| 1 | The partition wall supports a… | USPTO Backgrounds | Rewrite… | The partition wall collaborates… | [‘support’, ‘connect’] | [‘collaborate’, ‘attach’, ‘support’] |
| 2 | We are seeking to move forward… | Enron Emails | Rewrite… | We aim to commence the development… | [‘seek’, ‘move’] | [‘aim’, ‘commence’] |
| 3 | Monitor your RON (run-of-network)… | Pile-CC | Rewrite… | Keep a close eye on your RON… | [‘monitor’, ‘identify’, ‘add’] | [‘keep’, ‘spot’, ‘perform’, ‘include’] |
Source: The context or origin of the original sentence, such as “law,” “USPTO Backgrounds,” “Enron Emails,” “Pile-CC,” or “OpenWebText2.”
Sys: The instruction given to a language model (like GPT-4 or GPT-4 mini) to rewrite or paraphrase the original sentence. The instruction is: “Rewrite and paraphrase the following sentence using your own words. Focus on changing the structure and vocabulary while preserving the original meaning and tone. Only return the rewritten sentence.”
GPT: The rewritten or paraphrased version of the original sentence, as generated by GPT-4o mini.
verbs_human: A list of verbs extracted with Stanza from the original human-provided sentence.
verbs_GPT: A list of verbs extracted with Stanza from the sentence rewritten by GPT-4 or GPT-4 mini.
After that, I used a Python package for natural language processing called Stanza.
Yeah BUT WHAT IS STANZA?
If I had to explain it to a 5-year-old (or someone who hasn’t spent 10 days building a dataset)…
Stanza is like a super-smart helper that understands what we say or write, even if we speak in many different languages. Imagine that Stanza is a robot that reads words and knows what they mean, just like when you learn new words at school.
This helper can also break a sentence into small pieces, like words and names, and figure out who is doing what. It’s like a detective who finds all the hidden information in a sentence to know who the people are, what they are doing, and how they are doing it.
Now let’s be professional..
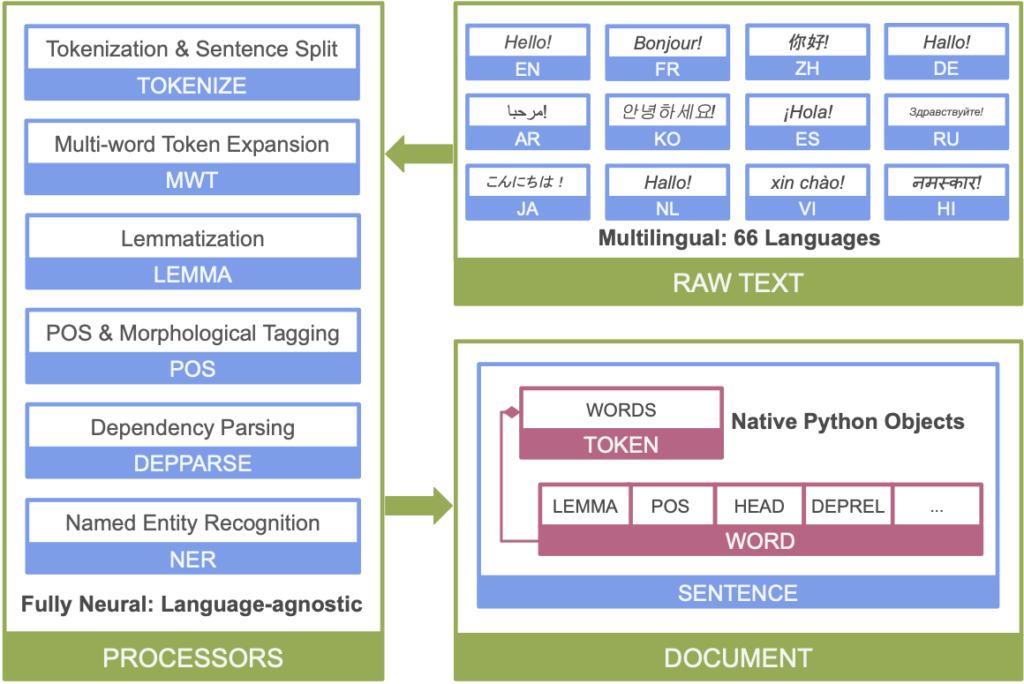
This toolkit provides tools that can be used in a pipeline to convert a text containing human language into lists of sentences and words, generate the base forms of these words, identify their parts of speech and morphological features, provide syntactic dependency structures, and recognize named entities. Stanza is designed to be compatible with over 70 languages, using the Universal Dependencies formalism.
Stanza is built with highly accurate neural network components that also allow for efficient training and evaluation with your own annotated data, leveraging the PyTorch library. The performance is much faster if the software is run on a machine with a GPU.
Additionally, Stanza includes a Python interface to the Java CoreNLP package, inheriting additional functionalities such as sentence structure analysis, coreference resolution, and linguistic pattern recognition.
To summarize, Stanza features:
- Native Python implementation requiring minimal efforts to set up;
- Full neural network pipeline for robust text analytics, including tokenization, multi-word token (MWT) expansion, lemmatization, part-of-speech (POS) and morphological features tagging, dependency parsing, and named entity recognition;
- Pretrained neural models supporting 70 (human) languages;
- A stable, officially maintained Python interface to CoreNLP.
Below is an overview of Stanza’s neural network NLP pipeline:
NOT ONLY A STANZA..
I tested the efficiency of various natural language processing packages, focusing on different SpaCy models before choosing Stanza. Specifically, I tested the following models:
SpaCy SM (Small Model): A lightweight and fast model, ideal for applications that require speed and low computational resource consumption. However, the accuracy of SpaCy SM can be limited, especially in complex contexts or on large datasets.
SpaCy MD (Medium Model): A medium-sized model that offers a good balance between speed and accuracy. It is more accurate than the SM model but still less resource-intensive compared to the Transformer-based model (TRF).
SpaCy TRF (Transformer Model): An advanced model that uses Transformer-based neural networks, such as BERT. This model is the most accurate among those tested, capable of capturing complex contexts and nuances in the text, but it requires significantly more computational resources and memory, making it less suitable for real-time applications or devices with limited capabilities.
Why I Chose Stanza
Balance Between Accuracy and Resources: Stanza offers high accuracy in extracting the correct verbs, similar to SpaCy TRF, but with more moderate computational resource usage compared to the Transformer-based model.
Error Management: Stanza demonstrated a slight superiority in minimizing errors and preventing irrelevant additions compared to SpaCy SM and MD, while maintaining a performance level close to SpaCy TRF.
Versatility: Stanza is designed to support many different languages and can be easily integrated into multilingual NLP applications, providing a significant advantage over SpaCy in certain contexts.
So, we’ve reached the end of this article. I hope you enjoyed today’s exploration, and… enjoy the dataset!
This is another small step toward understanding the language of LLMs.